Оффлайн данные¶
Для создания надежной автономной работы необходимо реализовать управление хранением данных. В этом могут помочь такие инструменты, как IndexedDB, Cache, Storage Manager, Persistent Storage и Content Indexing.
Для создания надежной автономной работы PWA необходимо управлять хранением данных. В главе caching вы узнали, что кэш-хранилище — это один из вариантов сохранения данных на устройстве. В этой главе мы покажем, как управлять автономными данными, включая сохранение данных, ограничения и доступные инструменты.
Хранение¶
Хранилище — это не только файлы и ресурсы, оно может включать и другие типы данных. Во всех браузерах, поддерживающих PWA, для хранения данных на устройстве доступны следующие API:
- IndexedDB: вариант объектного хранилища NoSQL для структурированных данных и блобов (бинарных данных).
- WebStorage: Способ хранения пар строк ключ/значение, использующий локальное хранилище или хранилище сеансов. Он недоступен в контексте сервис-воркера. Этот API является синхронным, поэтому его не рекомендуется использовать для хранения сложных данных.
- Кэш-хранилище: Как описано в модуле Caching.
{% Aside %} На поддерживаемых платформах можно также использовать FileSystem Access API для чтения и записи в и из локальной файловой системы пользователя с соответствующими правами. Поскольку вы записываете файлы непосредственно в файловую систему, браузер не будет выделять эти данные в квоту вашего origin, и любое другое приложение может взаимодействовать с этими файлами, если пользователь разрешит это. {% endAside %}
На поддерживаемых платформах можно управлять всеми устройствами хранения данных с помощью Storage Manager API. API Cache Storage и IndexedDB обеспечивают асинхронный доступ к постоянным хранилищам для PWA и могут быть доступны из главного потока, веб-рабочих и сервис-воркеров. Оба они играют важную роль в обеспечении надежной работы PWA в условиях нестабильной или отсутствующей сети. Но когда следует использовать каждый из них?
Используйте Cache Storage API для сетевых ресурсов, таких как HTML, CSS, JavaScript, изображения, видео и аудио, к которым можно получить доступ, запросив их по URL.
Для хранения структурированных данных используйте IndexedDB. К ним относятся данные, которые должны быть доступны для поиска или комбинирования в NoSQL-подобном виде, а также другие данные, например, данные о конкретном пользователе, которые не обязательно должны соответствовать URL-запросу. Обратите внимание, что IndexedDB не предназначена для полнотекстового поиска.
{% Aside 'caution' %} Все хранилища, независимо от того, как они используются, привязаны не только к PWA, для которого они предназначены, но и к их происхождению. Поэтому, если вы развертываете более одного PWA на одном источнике (что не рекомендуется), имейте в виду, что базы данных IndexedDB, кэш-хранилище и другие хранилища браузера будут разделять квоты между всеми сервис-воркерами и PWA. {% endAside %}
IndexedDB¶
Чтобы использовать IndexedDB, сначала откройте базу данных. При этом создается новая база данных, если она не существует. IndexedDB — это асинхронный API, но вместо промиса он принимает обратный вызов. В следующем примере используется библиотека idb library Джейка Арчибальда , которая представляет собой миниатюрную обертку с промисом для IndexedDB. Для использования IndexedDB библиотеки-помощники не требуются, но если вы хотите использовать синтаксис промисов, то библиотека idb является дополнительным вариантом.
В следующем примере создается база данных для хранения кулинарных рецептов.
Создание и открытие базы данных¶
Чтобы открыть базу данных, выполните следующие действия:
- С помощью функции
openDBсоздайте новую базу данных IndexedDB с именемcookbook. Поскольку базы данных IndexedDB являются версионными, то при внесении изменений в структуру базы данных необходимо увеличивать номер версии. Второй параметр — версия базы данных. В примере установлено значение 1. - Объект инициализации, содержащий обратный вызов
upgrade(), передается вopenDB(). Функция обратного вызова вызывается при первой установке базы данных или при ее обновлении до новой версии. Эта функция является единственным местом, где могут происходить действия. Действия могут включать создание новых хранилищ объектов (структур, которые IndexedDB использует для организации данных) или индексов (по которым будет производиться поиск). Здесь же должна происходить миграция данных. Обычно функцияupgrade()содержит операторswitchбез операторовbreak, чтобы каждый шаг выполнялся по порядку, в зависимости от того, какой была старая версия базы данных.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
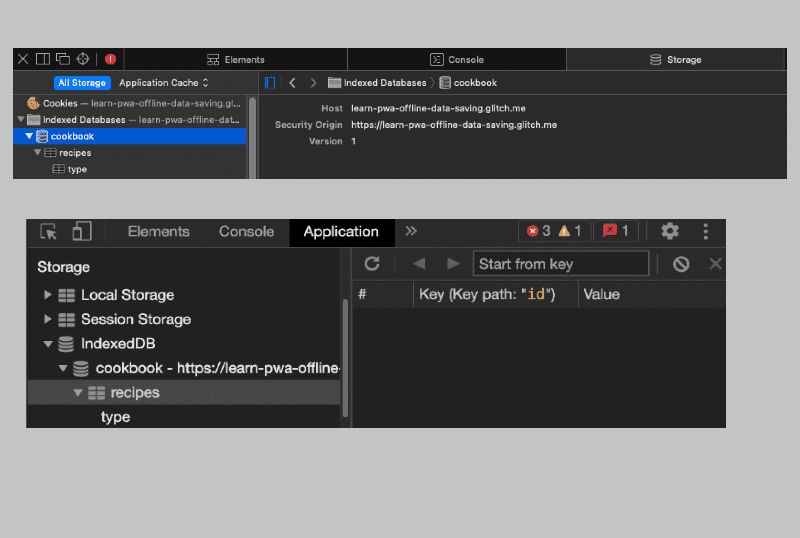
В примере создается объектное хранилище внутри базы данных cookbook под названием recipes, при этом свойство id устанавливается в качестве индексного ключа хранилища, а на основе свойства type создается еще один индекс type.
Давайте посмотрим на только что созданное хранилище объектов. После добавления рецептов в хранилище объектов и открытия DevTools в браузерах на базе Chromium или Web Inspector в Safari можно увидеть следующее:
Добавление данных¶
В IndexedDB используются транзакции. Транзакции объединяют действия в группы, поэтому они выполняются как единое целое. Они помогают обеспечить постоянное состояние базы данных. Кроме того, они очень важны, если у вас запущено несколько копий приложения, для предотвращения одновременной записи в одни и те же данные. Чтобы добавить данные, выполните следующие действия:
- Начните транзакцию с
mode, установленным наreadwrite. - Получить хранилище объектов, в которое будут добавлены данные.
- Вызовите
add()с сохраняемыми данными. Метод получает данные в виде словаря (в виде пар ключ/значение) и добавляет их в хранилище объектов. Словарь должен быть клонируемым с помощью Structured Cloning. Если вы хотите обновить существующий объект, то вместо этого следует вызвать методput().
Транзакции имеют промис done, который разрешается при успешном завершении транзакции или отказе от нее с ошибкой transaction error.
Как объясняется в документации по библиотеке IDB, если вы пишете в базу данных, то tx.done — это сигнал о том, что все успешно зафиксировано в базе данных. Однако полезно ожидать выполнения отдельных операций, чтобы видеть ошибки, приводящие к сбою транзакции.
1 2 3 4 5 6 7 8 9 10 11 12 | |
После добавления cookie рецепт окажется в базе данных вместе с другими рецептами. ID автоматически устанавливается и увеличивается с помощью indexedDB. Если выполнить этот код дважды, то будут получены две одинаковые записи о cookie.
Получение данных¶
Вот как можно получить данные из IndexedDB:
- Начните транзакцию и укажите хранилище или хранилища объектов, а также, по желанию, тип транзакции.
- Вызовите
objectStore()из этой транзакции. Обязательно укажите имя хранилища объектов. - Вызовите
get()с ключом, который вы хотите получить. По умолчанию хранилище использует свой ключ в качестве индекса.
1 2 3 4 5 6 7 8 9 | |
Попробуйте
Менеджер хранилища¶
Знание того, как управлять хранилищем PWA, особенно важно для правильного хранения и потоковой передачи сетевых ответов.
Объем хранилища распределяется между всеми вариантами хранения, включая Cache Storage, IndexedDB, Web Storage и даже файл сервис-воркера и его зависимости. Однако объем доступного хранилища варьируется в зависимости от браузера. Вряд ли он будет исчерпан: в некоторых браузерах сайты могут хранить мегабайты и даже гигабайты данных. Например, Chrome позволяет браузеру использовать до 80% всего дискового пространства, а отдельному origin — до 60% всего дискового пространства. В браузерах, поддерживающих Storage API, можно узнать, сколько дискового пространства еще доступно для вашего приложения, какова его квота и как оно используется. Следующий пример использует Storage API для получения оценки квоты и использования, а затем вычисляет процент использования и оставшиеся байты. Обратите внимание, что navigator.storage возвращает экземпляр StorageManager. Существует отдельный интерфейс Storage, и их легко перепутать.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
В Chromium DevTools, открыв раздел Storage на вкладке Application, вы можете увидеть квоту вашего сайта и объем используемого хранилища в разбивке по используемым ресурсам.
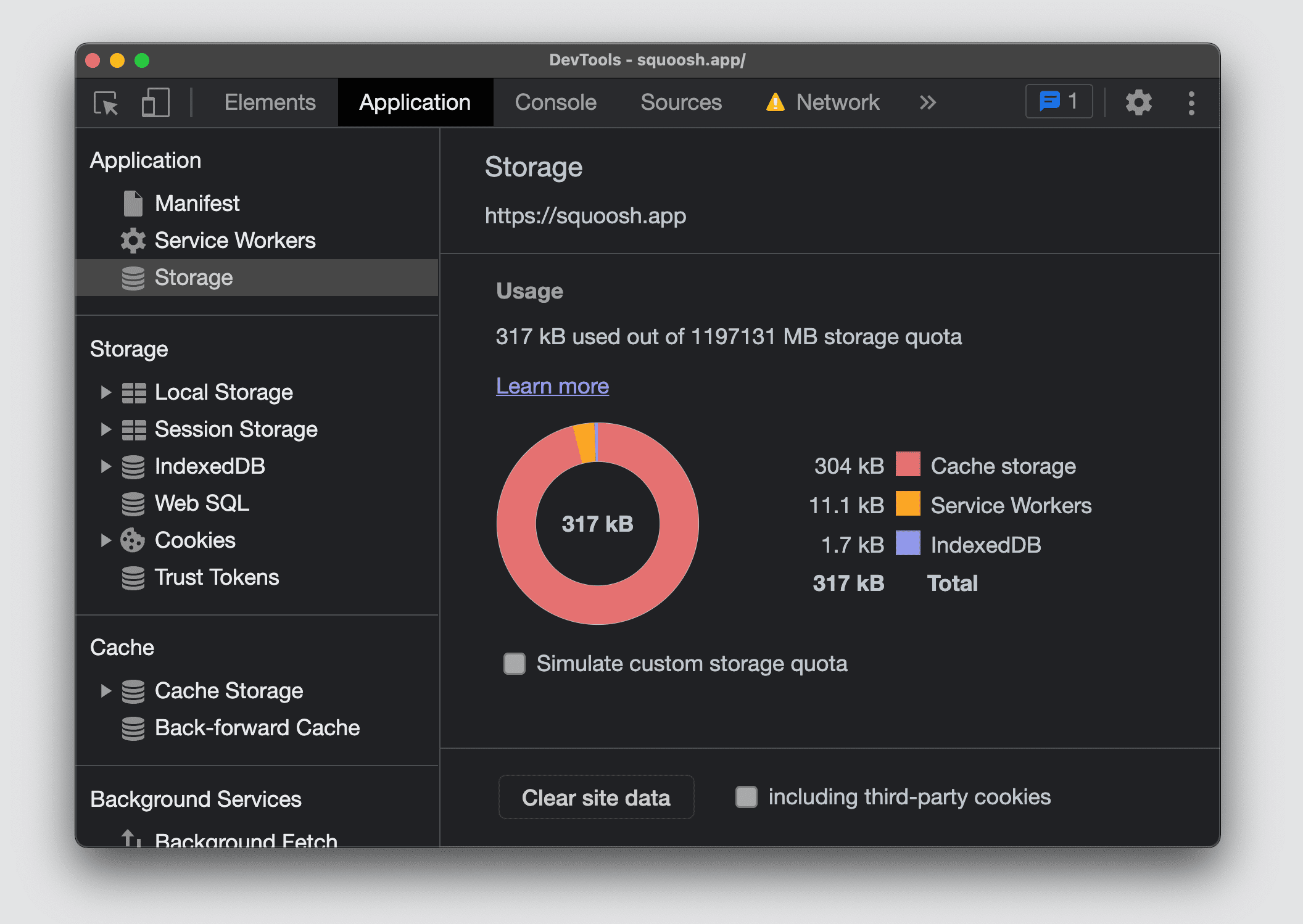
В Firefox и Safari нет сводного экрана для просмотра всех квот и использования хранилища для текущего источника.
Постоянство данных¶
На совместимых платформах можно запросить у браузера постоянное хранилище, чтобы избежать автоматического удаления данных после бездействия или в случае сжатия хранилища. Если запрос будет удовлетворен, браузер никогда не будет извлекать данные из хранилища. Эта защита распространяется на регистрацию сервис-воркера, базы данных IndexedDB и файлы в кэш-хранилище. Обратите внимание, что пользователь всегда остается в выигрыше и может удалить хранилище в любой момент, даже если браузеру разрешено постоянное хранение.
Чтобы запросить постоянное хранилище, вызовите функцию StorageManager.persist(). Как и прежде, доступ к интерфейсу StorageManager осуществляется через свойство navigator.storage.
1 2 3 4 5 6 | |
Также можно проверить, разрешено ли постоянное хранилище в текущем origin, вызвав StorageManager.persisted(). Firefox запрашивает у пользователя разрешение на использование постоянного хранилища. Браузеры на базе Chromium разрешают или запрещают постоянное хранение, основываясь на эвристике для определения важности содержимого для пользователя. Одним из критериев для Google Chrome является, например, установка PWA. Если пользователь установил в операционной системе значок для PWA, браузер может разрешить постоянное хранение.
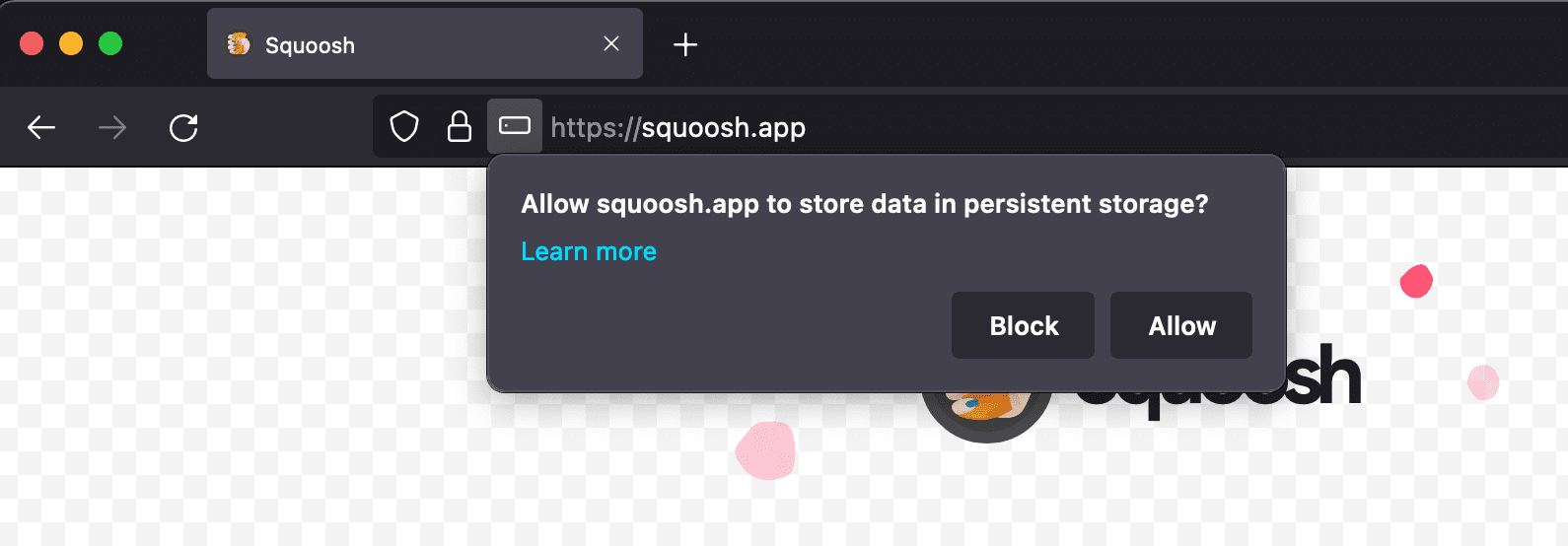
Интерфейс StorageManager имеет методы persist() и persisted(), которые возвращают промисы, разрешаемые булевым значением. Функция persist() запрашивает включение постоянного хранилища и возвращает результат, а persisted() возвращает текущее состояние, не изменяя его.
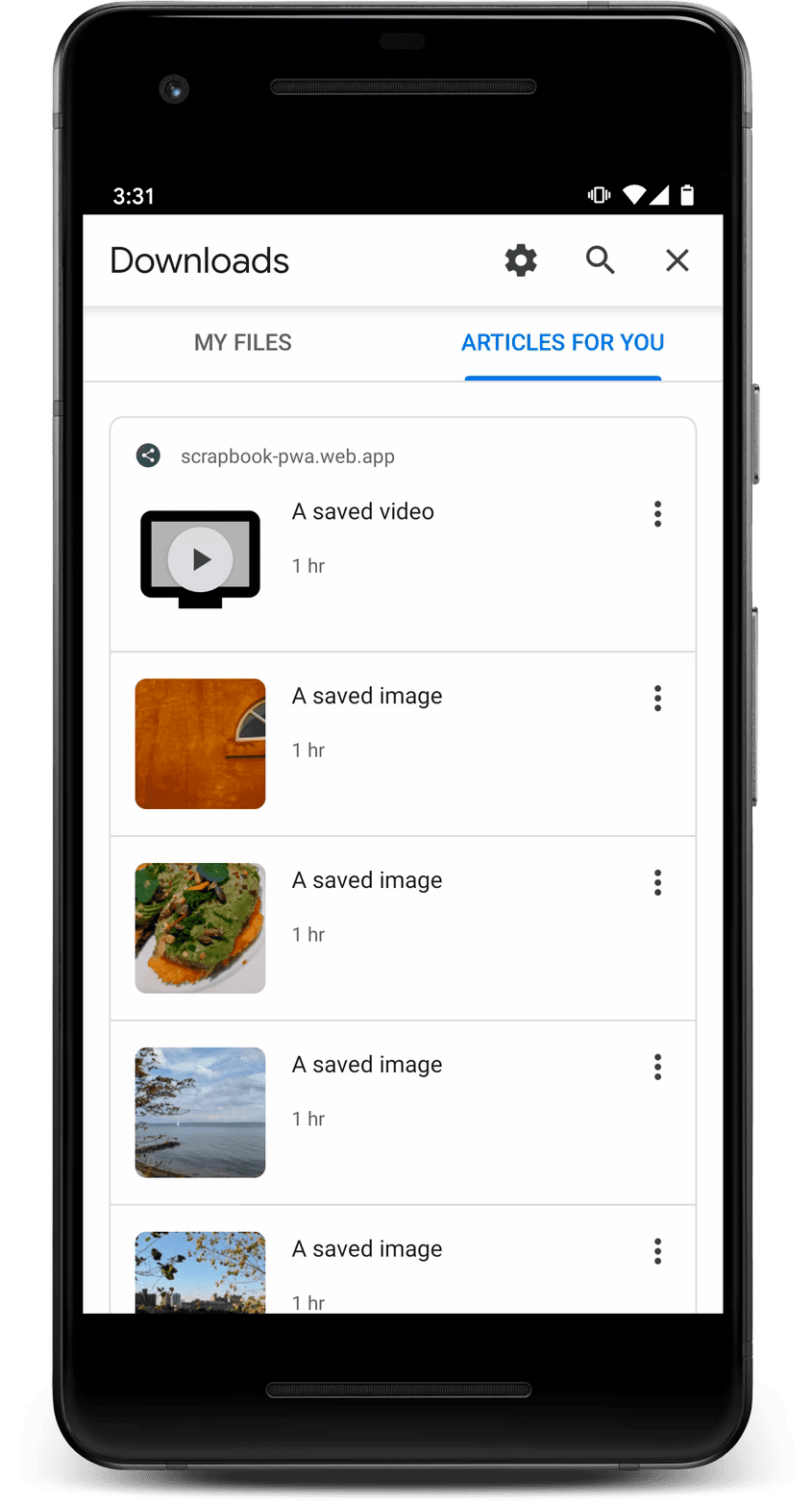
Content Indexing API — это экспериментальный API, доступный в некоторых браузерах Chromium, который позволяет вашему PWA открывать фрагменты контента, проиндексированные вами в автономном режиме. Если вы зарегистрируете готовый к работе в автономном режиме контент с помощью этого API, то пользователь будет видеть его в разделе "Загрузки" в браузере даже при отсутствии сетевого подключения.
Ресурсы¶
- Хранилище в Интернете
- FileSystem Access API
- Постоянное хранение данных
- MDN: Storage API
- MDN: Хранилище на стороне клиента
- Индексирование содержимого
Источник — Offline data